The future of inference acceleration could be changed dramatically by the input of artificial intelligence and its development for data centers.
With the new and emerging field of 'Edge AI,' this trend is changing, and technology like smartphones, drones, robots, surveillance cameras and industrial cameras will all have some kind of AI processing inbuilt within the near future.
Things get more interesting when inference is to directly take place on the imaging device itself. An interesting question to consider is how such a high-power technology can be used sustainably and efficiently outside of large data centers in the small resource-optimized embedded devices?
Some solutions and approaches that are designed to accelerate neural networks on edge devices efficiently are already in existence. However, out of these new approaches, only a select few are flexible enough to keep up with the rapid advancements and developments in AI.
Edge Intelligence
The term 'edge intelligence' describes a class of devices that can solve inference tasks "on the edge" of networks in conjunction with machine learning algorithms and neural networks.
In this context, a question which is increasingly asked is why artificial intelligence should be used more and more in embedded devices and why the industry's focus is now turning to Deep Learning and Deep Neural Networks?
To answer this question, it is important to focus less on AI and more on security, latency, bandwidth and decentralized data processing. It is important to focus on the core topics and the difficulties of modern Industry 4.0 applications.
One keen focus is on the reduction of the inherent competition for the bandwidth of the shared communication channel. This can be achieved with the filtration or conversion of high volumes of camera or sensor data into usable information already on the edge devices themselves.
Process decisions can then be made directly at the point of image capture without the challenges of data communication, thanks to this immediate data processing.
It may even be the case that, when considered from a security or technical perspective, dependable and consistent communication with a cloud-based or central processing unit is either undesirable or difficult to achieve.

Figure 1. The AI core "deep ocean core" developed by IDS hardware accelerates the execution of artificial neural networks on industrial cameras and enables inference times of a few milliseconds. Image Credit: IDS Imaging Development Systems GmbH
When encapsulated by edge devices in this way, acquired data also assists in the decentralization of data storage and processing, which in turn reduces the likelihood of a potential attack on the whole system. Indeed, it is important to note that for every organization, the security of the data generated and transmitted is crucial.
There is also a clear separation of job-specific tasks within distributed system intelligence. For instance, within any one factory, an image classification service may be required by hundreds of individual workstations in order to analyze different sets of objects at each station.
Nonetheless, there is a cost to hosting multiple classifiers in the cloud. It is necessary to find a cost-effective solution to train all of the classifiers in the cloud and send the models to the edge devices, which can be adapted to the respective workstation.
A classifier that makes predictions across all workstations is likely to perform worse than the specialization of each model. Additionally, in contrast to data center realization, these simple, special solutions also cut down on valuable development time. These, among many other reasons, reinforce the argument for outsourcing inference execution to edge devices.
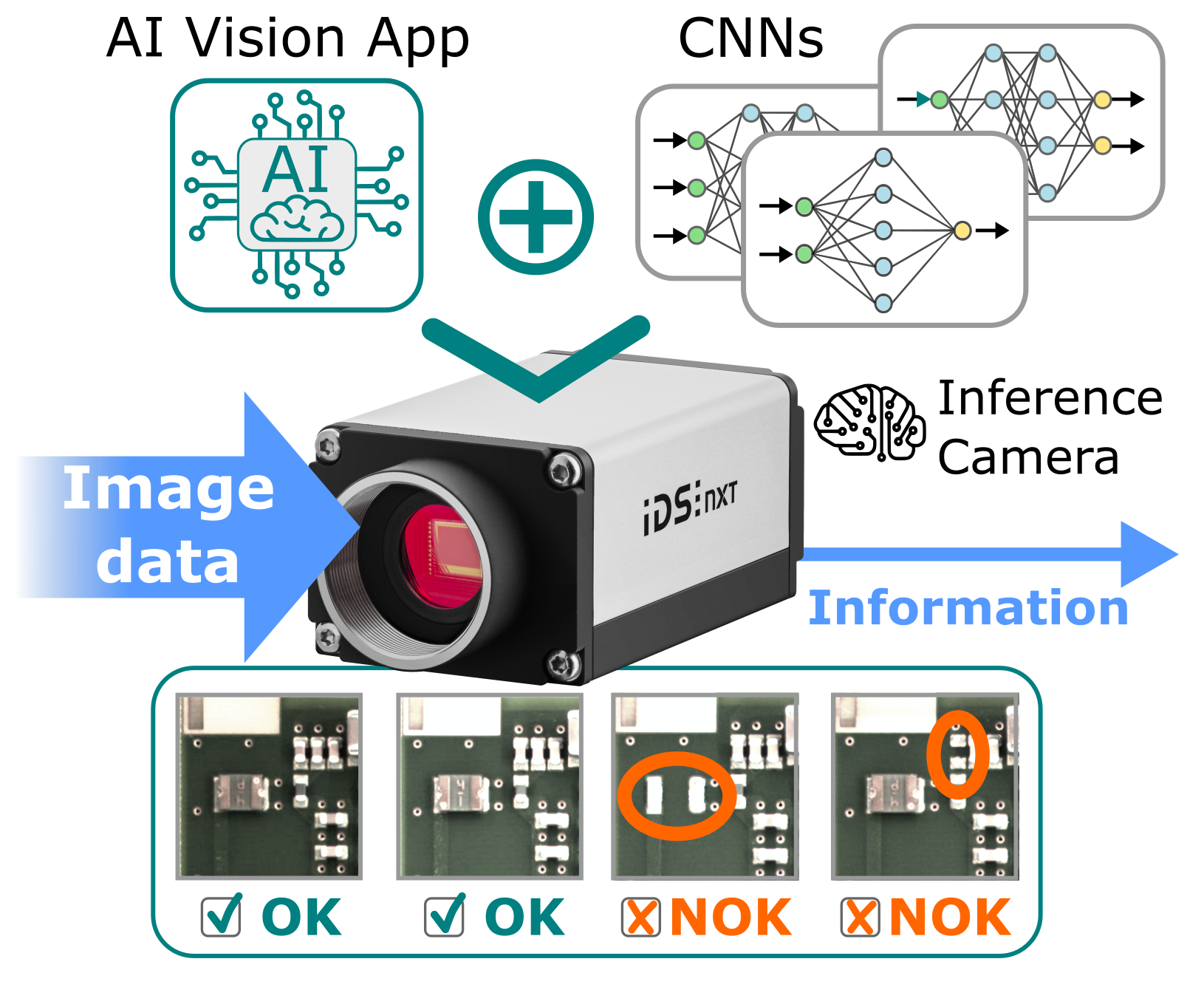
Figure 2. Intelligent edge devices reduce large amounts of sensor and image data. They generate directly usable information on the edge and communicate only this to the control unit. Image Credit: IDS Imaging Development Systems GmbH
Challenges
It is important to investigate why neural networks are deemed unsuitable for embedded use, along with establishing what the challenges of using them effectively "on the edge" may be.
Of course, it can be complex to perform AI inference tasks on edge devices. In general, edge computing is all about efficiency, which is why edge devices typically have reasonably limited amounts of storage, computing and energy resources to offer.
This, therefore, means that such devices must concurrently deliver high-performance values and low latency times while executing calculations with high efficiency - a complex ask. The supreme discipline, of course, accompanies the execution of CNNs.
CNN's have a particular reputation for requiring billions of calculations to process an input and being extremely computationally intensive. In principle, with millions of parameters describing the CNN architecture itself, they do not represent the ideal candidate when it comes to edge computing.
MobileNet, EfficientNet or SqueezeNet are more suitable for embedded use, as they are all examples of so-called "parameter-efficient" networks which require a smaller number of parameters to describe them. Memory requirements and computing demands are significantly reduced – which is just one of the systems' benefits.
The networks must be compressed in order to further reduce storage requirements. For instance, parameters which are not important can be removed by the process of "pruning" after training, or quantization can be used to reduce the number of bits for describing the parameters.
The reduction in CNN memory size results in a positive change to processing time, which brings our analysis to the last aspect of optimization.
A bespoke and specially tailored computational system created for such architectures must still be used (despite the use of compressed and parameter-efficient networks) to run AI efficiently on the edge.
Two basic system properties need to be considered for this purpose. The system must be flexible enough to support new developments of CNN architectures, in addition to the required efficiency we have already mentioned.
This is particularly important in the field of AI because new architectures and new layer types are approved by the development and research area every month. Things that are new and current today may become outdated by tomorrow. So, what are the best platform options?
Platform Selection
- It is undeniable that a CPU-based system offers the highest amount of flexibility. However, it must be noted that, unfortunately, CPUs are both extremely inefficient when operating CNNs and not particularly power-efficient either.
- A GPU platform performs the CNN execution with a high volume of power through its compute cores working in parallel. GPUs are highly flexible and are more specialized than CPUs. However, they are very power-hungry and can therefore naturally pose problems on the edge.
- In the field, the architecture of programmable FPGAs can be reconfigured and therefore adapted to new CNN architectures. FPGAs also function incredibly efficiently thanks to their parallel mode of operation, but it must be noted that their programming requires a greater degree of hardware knowledge.
- An obvious front-runner in terms of efficiency is a full ASIC solution as a customized integrated circuit. This is key because an ASIC solution has been designed to efficiently execute a given CNN architecture. Yet, if new or changed CNN architectures are no longer supported, flexibility could pose an issue.
At the current stage of AI development, FPGA technology is best suited for the realization of a CNN accelerator on edge devices, thanks to its high performance, flexibility and energy efficiency.
In addition, FPGA is a solution which is suitable for industrial use and therefore works long-term, thanks to the fact it can be modified at any time during the operation of the unit by updating with a new configuration file for special applications or CNNs.
Of course, it is key to note that one of the biggest obstacles in using FPGA technology is that programming is highly complex and can only be performed by specialists.
Development Strategy
A CNN accelerator was developed based on FPGA technology in order to execute neural networks in a "vision edge device," i.e., the versatile IDS NXT cameras.
This FPGA accelerator was named "Deep Ocean Core." However, rather than several specially optimized configurations for different CNN types, one universally applicable architecture was preferable in order to keep the handling of the FPGA as simple as possible in later use.
This means that if it consists of supported layers, the accelerator can run any CNN network.
Given that all regular layers (e.g., convolutional layers, squeezing excite layers, addition layers and various types of pooling layers) are already supported, it is key to note that basically any important layer type can be used.
The user, therefore, does not need any specific knowledge to create a new FPGA configuration and the issue of complex or difficult programming is effectively eliminated.
The deep ocean core is constantly evolving to support any new development in the CNN field, through the firmware updates of the IDS NXT cameras.
Deep Ocean Core
How does the universal CNN accelerator work, and which steps are needed in order to run a trained neural network? Firstly, the accelerator only needs "binary description," which details the layers that make up the CNN network (for which no programming is necessary).
However, the accelerator cannot understand the 'language' of a neural network. For instance, a neural network that is trained with Keras is in a special "Keras high-level language," which is incomprehensible to the accelerator.
The 'language,' therefore, must be translated into a binary format which resembles a form of "chained list." Each layer of the CNN network then turns into a node end descriptor which outlines each layer exactly. A complete concatenated list of the CNN in binary representation is the product of this translation process.
This process is automated by a tool. No specialized knowledge is necessary. At this stage, the generated binary file is subsequently loaded into the camera's memory and processing begins via the deep ocean core. At this point, the CNN network is now running on the IDS NXT camera.
Execution Flexibility
There are clear benefits of using a CNN representation as a chained list, particularly when it comes to accelerator flexibility. This facilitates the fast and seamless switch between networks. It is possible to load several "linked list representations" of different neural networks within the camera's working memory.
The deep ocean accelerator must point at the beginning of one of these lists in order to select a CNN for execution. The only outstanding task which much be undertaken is changing a "pointer value" to one of the list memories.
This simply refers to a straightforward write operation of an FPGA register: a task which can be performed quickly and as necessary.
The fast switch of CNN networks is so important. For instance, let us imagine that a company has a production line which boasts two different types of products running along it.
If the company wants to inspect its product quality, the company must first recognize the products' position and subsequently classify the quality (according to product-specific defects) based on that recognized product category.
This task could be solved by training a huge CNN network to both find the objects and concurrently classify them by simply pre-training a single possible failure case for each product group.
Although this approach could work, it is not cost-effective and could risk the network becoming both slow and large. Another difficulty of this approach will be achieving sufficiently high accuracy.
If the company had the ability to change the active CNN network rapidly and efficiently, the tester could decouple the localization and classification of different objects, as individual CNNs are easier to train. In this scenario, object recognition only needs to distinguish between two classes and provide their positions.
Two additional networks are trained solely for the respective product-specific properties and defect classes. Depending on the localized product, the camera application, entirely automatically, then decides which classification network is activated as a result in order to also determine the respective product quality.
Using this approach, the edge device works with reasonably simple tasks with few parameters. This approach results in the individual networks becoming much smaller, making them ideally suited for execution on an edge device thanks to a reduction in their need to differentiate features, allowing them to work faster and consume less energy.
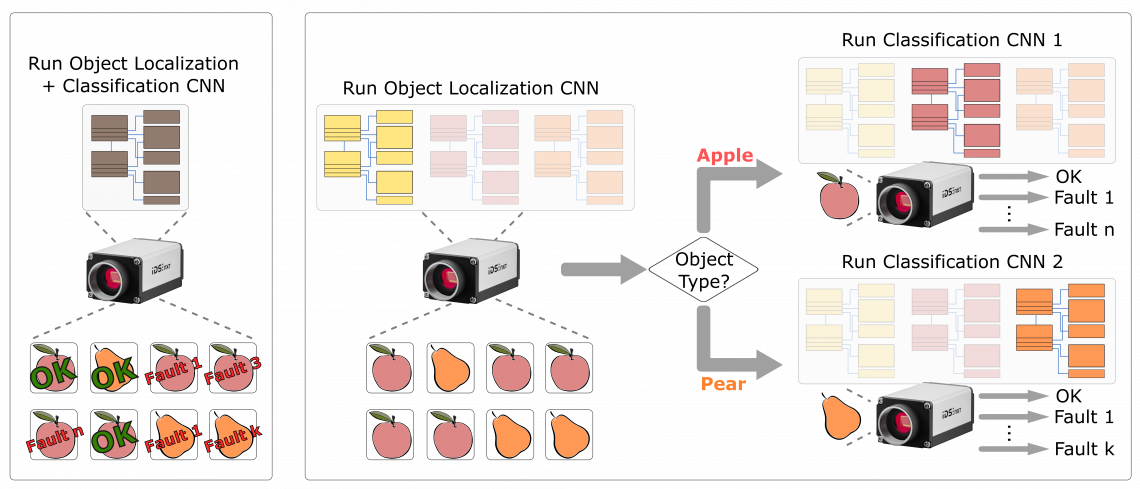
Figure 3. Being able to change the execution of neural networks on the fly allows image analysis to be divided into simpler inference workflows that are more efficient, faster and more stable on-camera. Image Credit: IDS Imaging Development Systems GmbH
Efficient and Performant
With 64 compute cores, the FPGA-based CNN accelerator in the IDS NXT inference cameras operates on a Xilinx Zynq Ultrascale SoC. MobileNet, SqueezeNet and EfficientNet are examples of well-known image classification networks which can achieve frame rates of up to 67 frames per second.
Twenty frames per second are possible even on network families such as Inception or ResNet, which are thought to be too complicated for edge computing. The 20 frame-per-second rate is, therefore, quite sufficient for many applications.
The performance of the deep ocean accelerator can be further developed thanks to the FPGA implementation. All cameras already in the field can benefit from firmware updates.
Power efficiency is even more vital when it comes to edge computing, as it signifies how many images per second a system can process per watt of energy. Power efficiency is a great metric when it comes to comparing different edge solutions.
Different CNN accelerators are compared in the following diagram. In the diagram, the following accelerators are compared, the deep ocean core as FPGA implementation, the classic CPU solution by a current Intel Core-i7 CPU, the GPU solution with a Jetson TX 2A, a Raspberry Pi as embedded CPU solution and finally, a fully ASIC solution represented by the Intel Movidius AI chip.
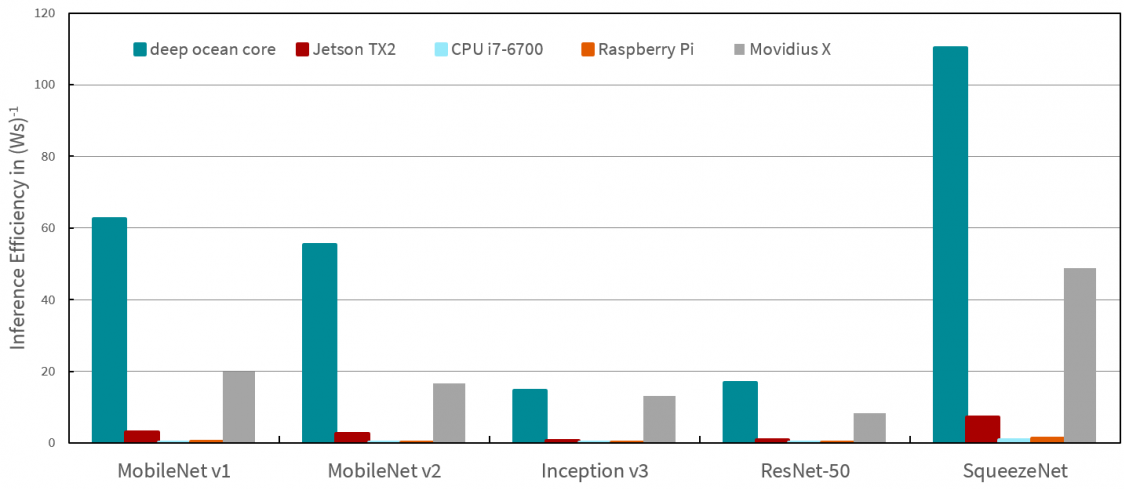
Figure 4. Especially for parameter-efficient networks, such as the MobilNets or the SqueezeNet, you can see that the FPGA architecture is a clear winner. It has the highest power efficiency among the systems compared. This makes the deep ocean core the preferred candidate for edge intelligence. Image Credit: IDS Imaging Development Systems GmbH
An All-In-One Inference Camera Solution
To ensure that the FPGA-based CNN accelerator is even easier to use, a complete inference camera solution - IDS NXT ocean - is offered by IDS which ensures that the technology is easily accessible to everyone.
Users of the system do not need any training or pre-existing knowledge in image processing, deep learning or camera / FPGA programming in order to successfully train and run a neural network.
This means that all users can immediately commence AI-based image processing. Tools, such as the FPGA-based CNN accelerator, which are demonstrably easy to use, remove the entry barrier to creating inference tasks in minutes, allowing them to run immediately on a camera.
In addition to the intelligent camera platform IDS NXT with the FPGA-based CNN accelerator, the overall concept of the IDS NXT ocean all-in-one AI solution also includes training software which is easy to use for neural networks.
Each component has been developed by IDS directly and, as a result, they have been designed to work seamlessly together. This simplifies the workflows, making the overall system more efficient.
Sustainable Edge Intelligence
Each of the possibilities offered to accelerate neural networks have their own individual advantages and disadvantages. If end users prefer to turn to fully integrated AI accelerators, such as the Intel Movidius, they must deal with the necessary components themselves in order to use AI for machine vision tasks.
Thanks to extensive documentation of the functional scope, ready-to-use chip solutions not only work efficiently and enable unit prices which are only possible in large quantities but can also be integrated into systems relatively easily and quickly.
However, their long development time is a huge problem in the AI environment - which changes every day.
The system components must fulfill other requirements in order to develop a universal, flexible and high-performance "edge intelligence." The ideal and optimal combination of performance, flexibility, sustainability and energy efficiency is to be found within an FPGA base.
"Industrial suitability," which is ensured by long availability and simple and long-term maintainability, is one of the most important requirements of an industrial product.
Today, a sustainable edge intelligence end-to-end solution which eliminates the need for end users to worry about AI updates and individual components is offered in the easy-to-use IDS NXT inference camera platform (combined with an FPGA CNN accelerator).

This information has been sourced, reviewed and adapted from materials provided by IDS Imaging Development Systems GmbH.
For more information on this source, please visit IDS Imaging Development Systems GmbH.