While the so-called negative volume segmentation technique has potential for applications in a wide range of areas, including construction and engineering, the scientists sought out literally the most jaw-dropping object to demonstrate the solution’s merits.
The study came out in Nature Scientific Reports.
This research offers an alternative look at the tedious problem of 3D image segmentation, which is widely encountered in medical diagnostics, machine engineering, and elsewhere
Dmitry Dylov, Principal Invesitagtor, First Pavlov State Medical University
PI Dmitry Dylov went on to say: “We began with the idea: Instead of seeking the exact contours of a 3D object, what if we segment the air that fills the gaps within its parts? These gaps are the absolute complements to the traditionally sought annotation labels. To test this approach, we geared up with the most complex 3D object we could find.”
The temporomandibular joint, or TMJ, is located on each side of the head in front of the ears, where two vertical projections of the lower jaw fit into the sockets in the skull’s temporal bones (fig. 1).
There is a soft cartilage disk that serves as a cushion between the bones of the joint. Because TMJ is a double joint that also combines hinge-like and sliding motions, it is a highly complex system exceedingly difficult to map in 3D.
To make sense of CT scans of a patient’s TMJ, experienced physicians spend hours using specialized software to build a 3D model of the joint.
This involves the tedious process of segmenting images to identify the precise contours of each of the two bones involved.
Once a properly segmented 3D model of the joint is available, the patient’s dentist, facial surgeon, or other physician can advise them on ways to treat TMJ-related issues.
These can stem from joint erosion, teeth clenching, arthritis, trauma, or congenital jaw deformities, and can cause pain in the joint and as far away from it as in the neck, as well as eating and speaking difficulties due to reduced TMJ mobility.
It has even been suggested that TMJ health might affect a person’s gait and psychological well-being.
While disorders in this joint tend to be treatable, they are challenging to diagnose, not least because of segmentation complexity.
By way of demonstrating the capacities of negative volume segmentation, the Skoltech group that came up with the approach managed to fully automate the tedious task of segmenting the CT scans of the TMJ.
Powered by machine learning, the new solution took just four seconds to process images that would otherwise take an experienced physician at least an hour to interpret, before they could be of use to patients with characteristic problems that may include jaw, ear, and facial pain, difficulty chewing and opening the mouth.
Our colleagues from Pavlov University came up with a protocol for segmenting TMJ scans in 3D manually — this used to be done in 2D and took even more time that way. We build on their protocol and introduce a new approach we call negative volume segmentation suitable for both humans [fig. 2] and machine annotation.
Oleg Rogov, First Author and Chief Developer, Skoltech
"It shifts the focus from segmenting the hard-to-contour bones of the joint to segmenting the gaps in between. Hence its name: negative volume segmentation.” Oleg Rogov went on to say.
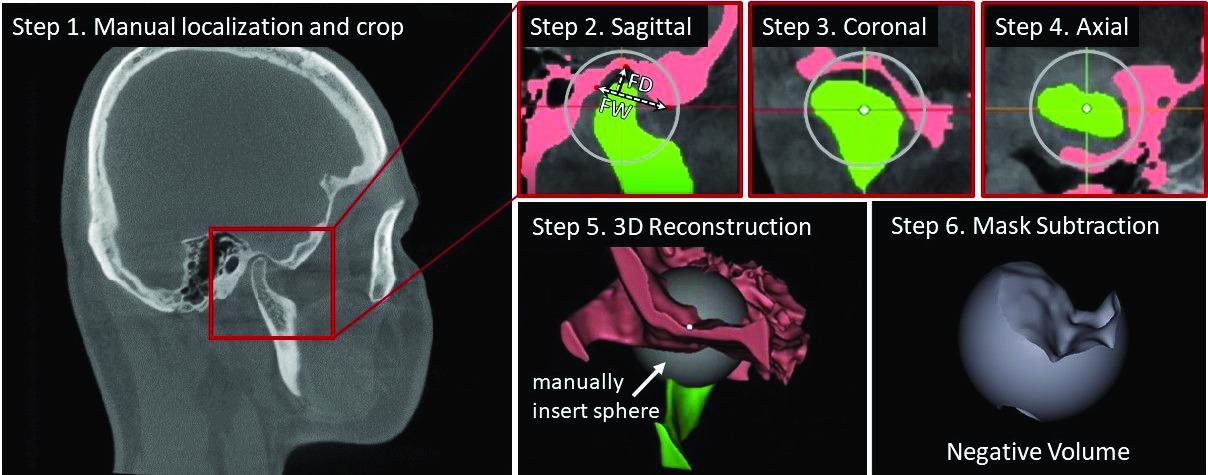
Figure 2. Steps in the manual annotation of the temporomandibular joint using the negative volume approach, which also underlies the automated procedure proposed by the authors of the study. This manual annotation takes about one hour and requires drawing masks around the complex structures of the mandible and the temporal bone in three views — sagittal, coronal, and axial — for each slice of the volume of interest, until the resulting 3D reconstruction allows to subtract the negative volume “ball” from a manually inserted sphere. Credit: Kristina Belikova et al./Scientific Reports
Using about 5,000 CT images of 50 patients provided by their Pavlov University collaborators, Skoltech researchers trained a neural network to segment TMJs in 3D so well the machine now actually outperforms human experts in terms of quality, in addition to being dramatically faster.
This makes it a great diagnostic tool that saves time and eliminates the need to invest in personnel training and expensive 3D visualization software.
The neural network locates the temporal bone and the mandible and proceeds to reconstruct the 3D volume between them based on CT slices of the TMJ (fig. 3).
To achieve this, it gradually inflates the volume of the mandible until it takes up the entire available space in the joint’s cavity.
According to the patent application filed by the team, the new model is applicable for diagnosing defects in contexts well beyond the medical analysis of TMJs.
It would work with other joints, such as the knee, and even with artificial structures in mechanical engineering, for example the pistons and cylinders in an engine.
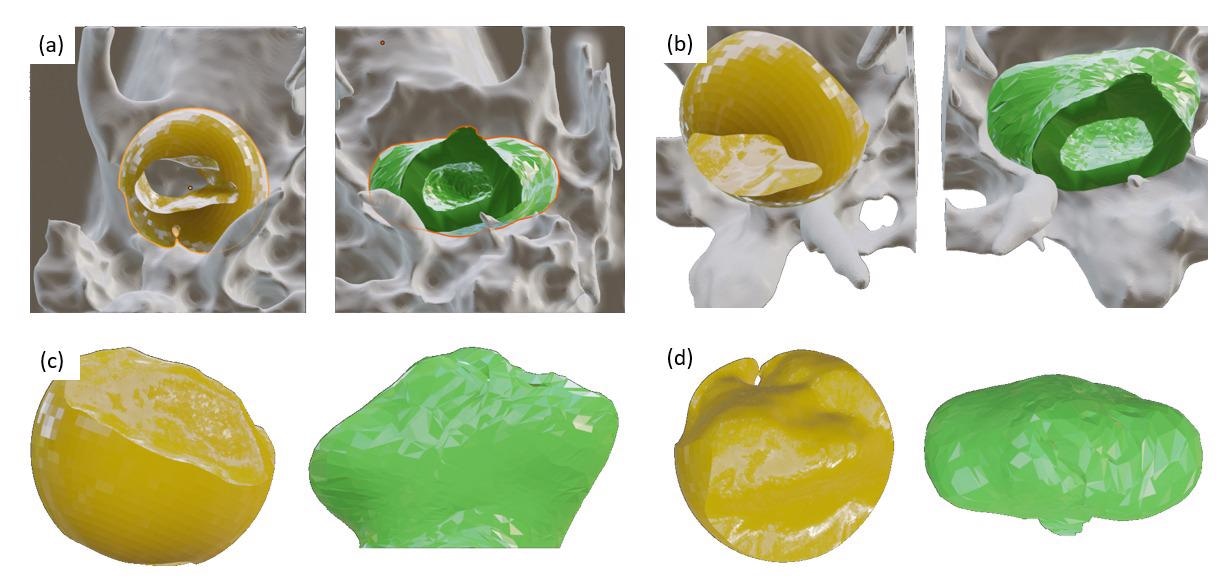
Figure 3. Rendered regions of the temporal bone, depicted in gray, with the temporomandibular joint negative volume shown in yellow (manually annotated) and green (machine-generated). Views: (a) axial, from bottom; (b) same, tilted; (c) lateral; (d) from above. Credit: Kristina Belikova et al./Scientific Reports